

Announcing the release of Connected Data Knowledge Graph: An open knowledge graph for the community by the community
- holly88883
- 5 days ago
- 6 min read

The Connected Data Knowledge Graph has arrived! What are you going to do with it?
In 2024, the Connected Data team embarked on an ambitious project: the Connected Data Knowledge Graph challenge.
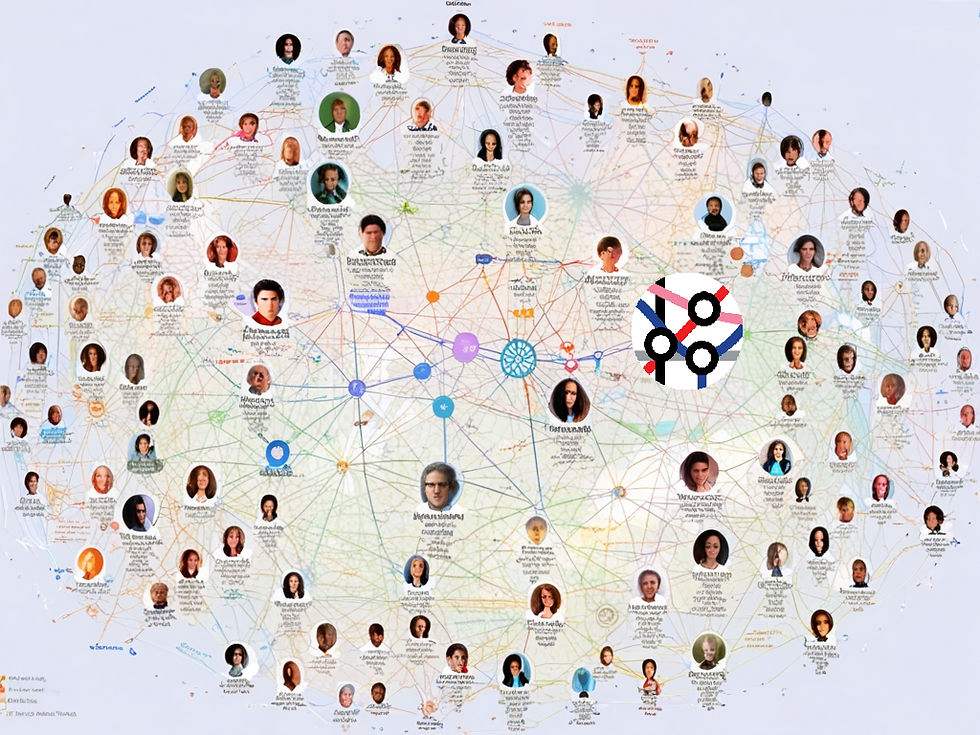
Building a curated Knowledge Graph based on the collective knowledge of ~300 experts. We have had the honor of hosting luminaries such as Gary Marcus, Gadi Singer, Kirell Benzi and Sir Nigel Shadbolt, as well as emerging speakers who went on to achieve great things.
There are 200+ expert and practical talks on Knowledge Graphs, Graph AI / Analytics / Data Science and Semantic Technology from previous Connected Data Conferences on YouTube.
People have little time to watch videos to learn and gather knowledge from experts and don’t know how to find the right videos. Thus, they miss opportunities to turn these great insights and best practices into something valuable.
By creating a knowledge graph based on the content our speakers have shared with the community, we are enabling everyone to learn and build on our collective knowledge.
Today, we are happy to announce the initial release of the Connected Data Knowledge Graph: CDKG v.0.1.
While this release marks a milestone for the CDKG, it represents just the beginning for our community.
You can use the application our team created to learn from the experts who have shared their knowledge with the Connected Data community
For example - are you interested in building an enterprise knowledge graph? Are you looking for some good resources to get started? This is exactly the type of question you can ask the CDKG.
You can build your own applications on top of the CDKG. For example - you can combine the CDKG with other knowledge graphs. Or you can build your own - our methodology is meant to inspire and be reproducible.
And last but not least, you can shape the direction the CDKG takes from now on.
For example - our current codebase relies heavily on the Kuzu open source graph database. But because the CDKG approach is designed to be independent of specific implementation, the recent shutdown of Kuzu does not mean that everything has to change.
Read on to find out what the CDKG brings to the table, and be inspired! What are you going to do with it?
If you have ideas and would like to contribute, click here to get in touch. Or simply browse the CDKG open source repository.
The Connected Data Knowledge Graph v.0.1
For about a year, the core CDKG team has been working behind the scenes. George Anadiotis, Dennis Irorere, Fidan Limani and Prashanth Rao each contributed in different areas.
Today, we are happy to announce the initial release of the Connected Data Knowledge Graph: CDKG v.0.1.
What this release includes:
Domain Metamodel: Technology agnostic, simple graph of entities and relationships
Property Graph Schema: Domain graph and Lexical graph
Metadata: Speakers and Sessions
Raw data: Session transcripts
Knowledge Graph: Data on Categories, Events, Speakers, Talks, Tags and their relationships
Evaluation data: Baseline questions and answers on the data included in the CDKG
Source code: Code used to construct and query the Knowledge Graph using Kuzu.
Getting Started with CDKG: Explore, Build, and Extend
The CDKG v.0.1 release provides multiple pathways for engagement, whether you're looking to explore existing knowledge or build something entirely new. At the most fundamental level, you can import the CDKG into Kuzu, run the provided source code, and immediately start querying the knowledge base.
For those who prefer visual exploration, Kuzu Explorer offers an intuitive interface to navigate the graph structure and discover connections between concepts, speakers, and sessions. The flexibility doesn't stop there—if you have a preferred graph database, you can import the CDKG into your tool of choice and work within your familiar environment.
Beyond simply exploring the existing graph, the CDKG provides a foundation for building and evaluating your own applications. The included evaluation data offers baseline questions and answers that can help you benchmark your implementations and ensure accuracy. This is particularly valuable if you're experimenting with different approaches to knowledge retrieval or question answering systems.

For those interested in pushing the boundaries of what's possible, there are numerous opportunities for experimentation and enhancement.
You might try substituting different LLMs for tag keyword extraction or Text2Cypher translation to compare performance and accuracy. The transcript data is rich with untapped potential—consider extracting additional entity types such as people, places, or organizations that aren't currently captured in the graph. You could also enrich the domain graph with more metadata to enable answering increasingly complex questions.
One particularly promising direction is adding vector embeddings as node properties. This would enable semantic search capabilities that, when combined with traditional graph traversal, open up possibilities for handling a much broader variety of questions. The combination of semantic similarity and structural relationships creates powerful synergies that neither approach achieves alone.
Lessons learned
Today’s release is just the tip of the iceberg. The journey to get to this point has been just as valuable. Here are some of the insights we shared with those who attended our Connected Data London 2024 Masterclass.
Building the CDKG taught us that starting with technology is a recipe for misalignment and inefficiency. It's tempting to jump straight into implementation, choosing databases and frameworks before fully understanding the domain. However, this approach inevitably leads to rework and frustration.
We learned that successful knowledge graph projects require careful upfront alignment across different disciplines—engineers who build the systems, domain experts who understand the content, and data modelers who bridge the gap between conceptual understanding and technical implementation.
Data modeling emerged as the cornerstone of our success, even though it's a slow and sometimes tedious process. The investment in proper modeling paid dividends by clarifying the domain, aligning our team around shared concepts, and ultimately driving better applications.
We discovered that good data modeling practices must be driven by two key factors: the applications you're building and a rigorous evaluation process. Without clear application goals, modeling becomes abstract and unfocused. Without evaluation, you can't tell whether your model actually serves its intended purpose.
Our meta-modeling approach added valuable flexibility to accommodate evolving requirements, though we acknowledge it also introduced additional complexity that teams should carefully consider.
LLMs proved to be helpful tools in our pipeline, but they're far from a silver bullet. While they excel at certain tasks like entity extraction and query translation, they have clear limitations in consistency, accuracy, and reasoning.
We learned to use them judiciously, always with human oversight and validation, rather than treating them as autonomous problem-solvers. This tempered approach helped us avoid the pitfalls of over-relying on AI while still benefiting from its capabilities.
Perhaps most importantly, we learned that knowledge graph projects require strong leadership and deliberate efforts to reduce friction. Making it easy for contributors to get involved—through clear documentation, accessible tooling, and welcoming onboarding processes—is essential for building community momentum.
We also discovered the importance of bridging different teams and technology stacks, particularly in the graph database world where the property graph and RDF communities often operate in parallel. Technical excellence alone isn't enough; sustainable open source projects need thoughtful governance, clear communication, and an inclusive culture that welcomes diverse perspectives and contributions.
Roadmap
Building on the foundation of CDKG v.0.1, our roadmap focuses on scaling and sustainability. We aim to keep maintaining and growing the Connected Data Knowledge Graph.
To do that, having now done a big part of the data modeling foundation work, we shift our focus to data engineering. Currently, our data processing is entirely manual. That was good enough to get CDKG v.0.1 out, but in order to scale, we need to automate data ingestion.
That will also enable us to increase CDKG’s coverage. Currently, only a fraction of the Connected Data knowledge base is included in the Connected Data Knowledge Graph. Automating our pipeline will enable us to populate the CDKG further.
We won’t limit ourselves to quantity only though. Our evaluation process thus far has been manual as well. Ideally, we would like to streamline it as well. That will also help us scale the effort as we add more content.
Last but not least in our roadmap is attracting new contributors, and using more graph database back ends. Our codebase and team are affected by the recent shutdown of Kuzu. Former Kuzu AI Engineer Prashanth Rao has been a key contributor, and much of our codebase uses Kuzu.
We are open to welcoming new people in the project who can help maintain the codebase and bring their ideas and enthusiasm to the table. We welcome people and tools from both the LPG and RDF world.
If you have ideas and would like to contribute, join our team of volunteers. Or let’s collaborate via the CDKG open source repository.
And have you secured your place at this year's Connected Data London conference? Sign up today to save 15% off your ticket with our advance rate, expiring on 31 October.


Comments